Leverage Metrics and Benchmarks to Evaluate LLMs
Navigate the LLM marketplace to find models that meet your needs, minimize costs, and maximize performance.
- The number of LLMs available is growing fast, and each has different functionalities and a unique value proposition, making the selection process and evaluation criteria increasingly complex.
- The true expenses of operating LLMs have yet to be fully passed on to consumers. As major providers begin to seek returns on their investments, you need to manage the risk of vendor lock-in and cost increases.
- You have trouble understanding release notes and blog posts that reference metric and benchmarking information and don’t know how to apply the results.
Our Advice
Critical Insight
Select an LLM based on model capabilities and performance to manage the risk of vendor lock-in. Be prepared to swap your LLM for a better performing or more cost-effective solution.
Impact and Result
- Use Info-Tech’s benchmark framework to assess LLMs along various performance axes to align your LLM with specific solution requirements.
- Use cost and performance metrics to understand costs at the onset of your LLM deployment to ensure you have a cost-effective solution that drives business value.
- Use benchmarks to assess the subjective performance characteristics of models and ensure you align LLM selection with specific capability requirements.
Leverage Metrics and Benchmarks to Evaluate LLMs
Navigate the LLM marketplace to find models that meet your needs, minimize costs, and maximize performance.
Analyst perspective
The AI services industry is quickly entering a period of LLM commoditization. Businesses will soon face challenges in not only adopting generative AI technology but also navigating an evolving marketplace where the most performant and cost-effective option is not obvious. While ChatGPT is a serious contender and a disruptor, it should not be a default product choice. Nor should OpenAI be a single go-to vendor.
Navigating this evolving landscape requires a partnership between business and technology leaders. Technologists will need to work with the business to buy, customize, or build models that address specific gaps and deliver specific value, all while balancing and optimizing tangible costs and measurable efficiencies against specific performance requirements.
Info-Tech is happy to provide its members with a conceptual framework that is aligned with systems engineering principles to understand the performance of models. The framework is aligned with a large list of benchmarks that can be used to define and assess critical solution requirements. Though the benchmarks themselves will undoubtedly evolve over time, the framework should continue to help frame future selections against design goals.
LLMs offer interesting opportunities, and finding the right model for your needs is a new skill for CTOs everywhere to master.

Dr. Justin St-Maurice
Principal Research Director
Technology Services
Info-Tech Research Group
Executive summary
Your Challenge
You lack a systematic method to articulate your specific needs capabilities required in an LLM and find it challenging to match your requirements with the right model.
You struggle to evaluate the business value of your LLM and find it difficult to align costs and performance with your business outcomes.
You have trouble understanding release notes and blog posts that reference metric and benchmarking information and don't know how to apply the results.
Common Obstacles
The number of LLMs available is growing fast, and each has different functionalities and a unique value proposition, making the selection process and evaluation criteria increasingly complex.
The true expenses of operating LLMs have yet to be completely passed on to consumers. As major providers begin to seek returns on their investments, you need to manage the risk of vendor lock-in and cost increases.
You don't know how to translate LLM benchmarks into real-world performance measures, which complicates the process of selecting the best LLM for your needs.
Info-Tech's Approach
Use Info-Tech's benchmark framework to assess LLMs along various performance axes to align your LLM with specific solution requirements.
Use cost and performance metrics to understand costs at the onset of your LLM deployment to ensure you have a cost-effective solution that drives business value.
Use benchmarks to assess the subjective performance characteristics of models and ensure you align LLM selection with specific capability requirements.
Info-Tech Insight
Select an LLM based on model capabilities and performance to manage the risk of vendor lock-in. Be prepared to swap your LLM for a better performing or more cost-effective solution.
Picking the right LLM is key
AI service providers need to balance cost and performance by finding the best LLM for today while preparing to leverage a roster of purpose-specific LLMs tomorrow.
Develop cost strategies.
LLM providers have made huge upfront investments and expect to deliver valuable savings (McKinsey, 2023). Expect future cost increases when providers shift toward the profitability phase.
Powerful LLMs require significant electrical power and water (ADaSci, 2024). Without addressing resource consumption, scaling AI will create energy scarcity and increase operating costs.
Get ready for LLM commoditization (DeepLearning, 2024). Avoid vendor lock-in, build around a competitive landscape mindset, and position vendors to compete for your business (Medium).
Develop performance strategies.
Different models have different strengths and weaknesses. Some have better interactive performance, others have impressive cognitive capabilities, and some are designed with a stronger focus on ethics, equity, and safety.
There will be important performance tradeoffs. If you try to maximize all dimensions of your LLM, it will be all-knowing but expensive to operate and difficult to maintain.
More novel isn't necessarily more useful. Stay focused on the value of new capabilities.

Initial ChatGPT Prompt [July 5, 2024]: I want to draw a comic, in a cartoony style that is one panel. I want to see an LLM (personified as an AI) say to its parents, crying, as though telling a sad story, "... And then he said I didn't need a high SAT score to pump gas!", sobbing.
It's more nuanced than assessing accuracy
Performance measures can be both objective and subjective.
Accuracy is a useful, objective measure for tasks with clear right or wrong answers. When LLMs are applied to more nuanced tasks involving human-technology interaction, edge cases are limitless, and performance measurement is more subjective.
Outputs can be objectively accurate without being contextually accurate. For example, an LLM could provide accurate technical information but deliver it in a manner that is perceived as inappropriate or offensive.
Subjective inputs require an element of subjective measurement. As LLMs theoretically can handle a near-infinite number of possible prompts, including opinions, contextual questions, and adversarial inputs, the idea of straightforward correctness is difficult to make fully objective.
Higher education professionals understand that objective scantron exams can't effectively measure subjective English literature competencies.
Find the best LLM today
Is an LLM that can develop websites, write stand-up comedy, and produce unlimited cat memes the best option on the table?
Using an overly complex solution for a simple problem is costly. Use metrics and benchmarks to drive business value by choosing an LLM that fits the need instead of maximizing its features and capabilities.

Don't anthropomorphize your LLM!
Anthropomorphization occurs when something inanimate is attributed human traits, such as emotion, loyalty, or preference. Though they may emulate human and social characteristics, LLMs are merely complex models that process inputs and outputs according to their programming.
LLMs are programmatic components that can and should be replaced as needed. Embrace the flexibility to swap them out for more efficient and cost-effective models that better meet the evolving needs and value demands of your organization.
Get ready to manage a roster tomorrow
Coordinating tasks through a fleet of specialized LLMs and smaller AI models will pave the way to cost effectiveness and value.
Scale out your performance through orchestration. Use metrics and benchmarks to optimize total system performance, deploy the most cost-effective LLMs, and identify new candidates for your fleet.
Benefits of multi-AI paradigms:
Isolate and fine-tune tasks through specialized LLMs to enhance performance and enable systematic troubleshooting.
Strategically recycle capabilities, knowledge, and intellectual property to modularize tasks.
Enable LLM swapping as the global catalog grows and more efficient technologies become available.
Reduce dependency on any single model and enable integration of new technologies.
Control the balance of creativity and consistency by leveraging the strengths of each LLM.
Buy, tune, or train an LLM?
LLMs can be purchased, fine-tuned, or trained from scratch.
Prompt a generative pretrained transformer (GPT) model |
Fine-tune a |
Train your own model |
|---|---|---|
Purchase a pretrained LLM (or use an open-source one) for a quick, ready-to-use solution that allows you to leverage AI capabilities with minimal setup and no training data. Pretrained models offer the convenience of ongoing improvements by the vendor and can perform a wide range of tasks, but they may lack consistency and require skillful prompting. |
Fine-tune an existing LLM to enhance its relevance and performance for your specific needs. Aim for a balance between customization and operational efficiency. This strategy enables significant improvement in model utility without the extensive resources and time typically required to train a model from scratch. |
Train and customize an LLM based on your unique organizational needs and private data. Ensure privacy and leverage opportunities to lead the market in specialized applications. Though resource intensive, this strategy provides full control over the model's architecture and training, making it ideal for addressing specific challenges and aligning closely with your strategic priorities. |
Regardless of your decision…
You need to measure and benchmark LLM performance and constantly consider new models. Overly-specialized training might necessitate additional models to cover all needs, while too broad an approach could diminish quality and consistency, leading to confusion and less effective solutions.
Info-Tech Insight
Fine-tuning models, or training your own, is a complex investment of time and resources that requires high maturity and good data.
Unique LLMs are valuable intellectual property assets that can be licensed, sold, or strategically leveraged in mergers and acquisitions. Consider the opportunity to enhance your company's market position and value with an LLM investment.
Metrics and benchmarks are important tools in your consulting service toolbox
They are complimentary ways to measure your LLM's performance.
Aspect |
Metrics (Objective) |
Benchmarks (Subjective) |
|---|---|---|
Definition |
Specific quantitative measures used to evaluate aspects of an LLM's performance. |
A set of standards or criteria used to assess the overall effectiveness of an LLM against defined expectations or other models. |
Purpose |
To provide detailed insights into the performance, accuracy, and behavior of an LLM on specific tasks. |
To provide a context within which to interpret performance, allowing comparison of an LLM to industry standards and competitive models. |
Use |
To monitor and report on various dimensions of an LLM, such as accuracy, speed, and resource consumption. |
To validate and compare the capabilities of an LLM against predefined criteria or competitive models with similar tasks. |
Use metrics and benchmarks to evaluate LLMs

Info-Tech Insight
Select an LLM based on model capabilities and performance to manage the risk of vendor lock-in.
Be prepared to swap your LLM for a better performing or more cost-effective solution.
Assess your model candidates in context
1. Define your solution requirements |
2. Prioritize LLM performance requirements |
3. Use metrics, benchmarks, and leaderboards to identify candidate models |
|---|---|---|
|
 |
|
Interested in a workshop to help sort out requirements?
Consider Launch Your AI Proof of Concept.
1. Define your solution requirements

Align human need and technology outcomes with the support of a human-tech ladder and systematically analyze requirements and constraints at multiple levels of need.
Identify challenges and unknowns during solution development and frame them as learning outcomes that scaffold concepts to be understood, applied, and leveraged for creative innovation.
Use our solution library to understand our design methodology while exploring new concepts and ideas for LLM technology.
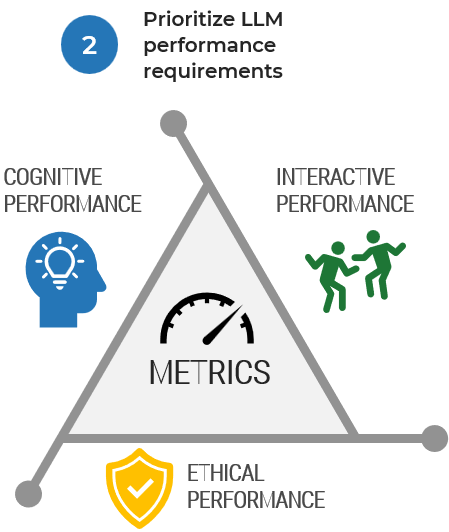
2. Prioritize LLM performance requirements
Rank the following statements in order of importance to describe your LLM performance priorities.
- The LLM needs to be proficient in natural language understanding.
- The LLM needs to be proficient in natural language generation.
- The LLM needs to be proficient in semantic analysis.
- The LLM needs to be capable of knowledge retrieval and application.
- The LLM needs to be logical in reasoning and inference.
- The LLM needs to be adaptable and capable of learning from new data.
- The LLM needs to be proficient in multiple languages and culturally aware.
- The LLM needs to be ethical and aware of biases.
- The LLM needs to have domain-specific expertise.
- The LLM needs to be engaging and maintain interactivity.
- The LLM needs to be accurate in mathematics and algebra.
- The LLM needs to be capable of contextual understanding and dialog skills.
- The LLM needs to be cost effective in operation.
- The LLM need to generate code and analyze data.
3. Use metrics, benchmarks, and leaderboards to identify model candidates
Metrics |
Benchmarks |
Leaderboards |
|---|---|---|
Metrics directly measure model performance by capturing performance, cost, and efficiency data. |
Benchmarks facilitate the comparison of model performance by using standard datasets, tests, and tasks.
|
Leaderboards publish ranked results for different models based on a variety of metrics and benchmarks. |
Pages 17 to 20 |
Pages 21 to 33 |
Page 34 |
Use metrics to assess your LLM
Metrics directly measure model performance by capturing performance, cost, and operations data.

Performance metrics
Metrics are raw statistics that quantify performance.
Metric |
Description |
|---|---|
Accuracy |
Measures the proportion of correct predictions among the total number of cases processed. |
Average |
Often used to summarize or aggregate results from multiple metrics. |
BLEU score |
Compares machine-translated text to one or more reference translations. |
Exact match |
Typically used in question-answering systems to measure the percentage of predictions that exactly match any one of the accepted truth labels. |
F1 score |
The combination of precision and recall used to consider both false positives and false negatives in binary classification. |
Latency |
Measures the time it takes for a model to return a prediction. Critical for evaluating the efficiency of real-time systems. |
Perplexity (PPL) |
Used in language models to measure how well a probability distribution predicts a sample. A lower perplexity indicates the model is better at predicting the sample. |
Precision/reliability |
Measures the accuracy of positive predictions. |
Recall |
Measures the coverage of actual positive cases. |
ROUGE score |
A set of metrics used to evaluate the automatic summarization of texts and machine translation. Includes measures such as how many n-grams in the generated text match the reference text. |
Word error rate (WER) |
Commonly used to measure the error rate in speech recognition by comparing the transcribed text with the reference text. |
Additional metrics can be found at https://huggingface.co/metrics.
Info-Tech Insight
Focusing on a single metric leads to behavioral changes and data distortions.
Focusing on a single metric often yields behaviors and consequences that aren't in the spirit of your desired outcome. Blend and counterbalance several metrics that are in tension with each other to understand tradeoffs.
Cost metrics
Measure direct capital and operational LLM expenses.
Metric | Description |
|---|---|
API calls | The number of API calls used against a model, which can be used as a component of billing. |
Tokens | The number of tokens processed by the LLM, often related to billing and usage tracking. |
License costs | The direct monetary expenses associated with operating the LLM, including licensing fees and subscriptions. |
Energy costs | The amount of electrical power consumed by the LLM during operations. |
Infrastructure costs | The costs related to the physical or cloud infrastructure required to support the LLM, including servers and storage. |
Maintenance costs | The ongoing costs of maintaining and updating LLM systems, including personnel and software updates. |
Training data costs | The costs associated with acquiring, cleaning, and preparing data used for training the LLM. |
Info-Tech Insight
Over time, GPT models leveraging prompts become more expensive than fine-tuned models.
GPT models leverage complex, cascading prompts to deliver flexibility. These prompts require a lot of tokens to do specific tasks, which can impact billing under usage-based pricing models.
Fine-tuned models are adapted from pretrained models by training them further on a specific dataset tailored to a particular task or domain. While they require more upfront investment and resources for training, these models can save money over time as they operate with fewer tokens per task, reducing cost per interaction.
Operational metrics
Measure operational factors associated with LLM use.
Info-Tech Insight
Use operational metrics to enhance efficiency, measure environmental impacts, and benchmark reliable services.
Operational metrics will vary from organization to organization and should be adjusted to reflect your business model and goals.
Metric | Description |
|---|---|
FLOPS (floating point operations per second) | Measures computational performance, important for understanding the processing power an LLM requires. |
Bandwidth use | The amount of data transmitted over a network, which can affect costs, especially in cloud-based models. |
Model update frequency | The frequency of required updates to the model, affecting the overall cost of keeping the model effective and secure. |
Carbon footprint | An environmental cost metric that quantifies the carbon emissions associated with the energy used by LLMs. |
Uptime | Measures the reliability of the LLM's services. |
Use benchmark data to assess performance
Benchmarks facilitate the comparison of model performance by using standard datasets, tests, and tasks.
COGNITIVE |
INTERACTIVE BENCHMARKS |
ETHICAL BENCHMARKS |
||
|---|---|---|---|---|
pages 23-29 |
pages 30-31 |
pages 32-33 |
||
Math, coding, and logical problem-solving
|
Language understanding and reasoning
|
Knowledge and multidisciplinary integration
|
|
|
Leverage Metrics and Benchmarks to Understand Leaderboards page 34
Leverage benchmark research and repositories to apply theory with practical tools
Research paper |
Project repository |
|---|---|
The research paper provides the theoretical foundation, scientific methodology, and intended goals behind the benchmark. It explains the principles, hypotheses, and experiments that underlie the benchmark's creation and application to the field of AI. It helps understand the rationale, scope, and scientific context of the benchmark. |
The project repository is a practical resource containing the code, datasets, and tools to implement and experiment with the benchmark. It provides the tools to apply theoretical concepts, including documentation, open-source scripts, and datasets. It helps replicate benchmarks and integrate them into larger assessments, projects, and initiatives. |
COGNITIVE PERFORMANCE BENCHMARKS
MATH, CODING, AND LOGICAL PROBLEM-SOLVING BENCHMARKS
Benchmark | Description | Research Paper | Project Repository |
|---|---|---|---|
AQuA-RAT | Tests algebraic problem-solving with a dataset that challenges models to answer natural language questions that require mathematical reasoning. Emphasizes logical deduction and numerical skills. | ||
CodeXGLUE | Assesses code synthesis, comprehension, and translation. Evaluates an LLM's technical and programming capabilities. | ||
GSM8K | Assesses the ability to solve grade-school math problems. Focuses on basic arithmetic operations and problem-solving skills. | ||
GSM-Plus | Extends GSM8K with more complex math problems that test higher levels of mathematical reasoning. | ||
HumanEval | Presents coding challenges to test an LLM's ability to generate syntactically and functionally correct code solutions. | ||
MATH | Challenges LLMs with complex mathematical problems that require detailed step-by-step solutions. Emphasizes computational skills. | ||
MBPP | Assesses basic Python coding tasks to evaluate coding proficiency and functional correctness in a controlled setting. | https://github.com/google-research/google-research/tree/master/mbpp | |
PIQA | Assesses physical interaction scenarios to test an LLM's understanding of practical, real-world problems, such as fitting an elephant through a doorway. | ||
SWE-bench | Tests an LLM's ability to generate code and resolve issues and bugs. Evaluates accurate and logical coding abilities. |
*Demonstrative subset of benchmarks. Due to the evolving nature of LLMs and benchmarking datasets, this is not an exhaustive or complete list for the category.

About Info-Tech
Info-Tech Research Group is the world’s fastest-growing information technology research and advisory company, proudly serving over 30,000 IT professionals.
We produce unbiased and highly relevant research to help CIOs and IT leaders make strategic, timely, and well-informed decisions. We partner closely with IT teams to provide everything they need, from actionable tools to analyst guidance, ensuring they deliver measurable results for their organizations.
What Is a Blueprint?
A blueprint is designed to be a roadmap, containing a methodology and the tools and templates you need to solve your IT problems.
Each blueprint can be accompanied by a Guided Implementation that provides you access to our world-class analysts to help you get through the project.
Talk to an Analyst
Our analyst calls are focused on helping our members use the research we produce, and our experts will guide you to successful project completion.
Book an Analyst Call on This Topic
You can start as early as tomorrow morning. Our analysts will explain the process during your first call.
Get Advice From a Subject Matter Expert
Each call will focus on explaining the material and helping you to plan your project, interpret and analyze the results of each project step, and set the direction for your next project step.
Unlock Sample Research







{kind=link}